【エントリー部門】
アイディア部門
【応募者属性】
社会人
【応募者名】
Linked Open処理の実装
【エントリー作品のURL】
http://www.slideshare.net/zuhitoslide/20160117lod-challenge-bluemix-57174977
【エントリー作品の権利指定】
CC0
【利用しているオープンデータ】
Wikipediaのダンプデータを使うことを検討
http://dumps.wikimedia.org
【利用しているパートナーリソース】
IBM Bluemix
【エントリー作品の詳細説明】
(図を用いて分かりやすくしたスライドも作成しましたので、上記スライドもご参照ください)
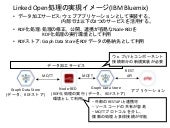
[Linked Open処理の概要]
今回提案したLinked Open処理とは、ボランティア同士でRDF化処理とデータを共有し、データを自由に加工できる処理である。本サービスのポイントは3つある。
1つ目は、RDF処理プログラムをオープンにする点である。これによってボランティア同士が、プログラムの内容を修正し、より適切なRDFデータに加工できる。またデータを多段階でクレンジングする場合、前の処理仕様が把握できるため、以降の処理で重複した不要な処理をなくせる等の改善ができる。
2つ目は、RDF化処理を実行する環境をオープンにする点である。大量のデータをRDF化するには、個人で所有しているPCでは不可能である。そのため、クラウドサービスとして実行する環境を提供し、大量のデータを加工できるようにする。また、大量のデータをインターネット越しにダウンロードとアップロードを行い、他のユーザと共有することも個人の回線では困難である。クラウドサービスとして提供することで、異なるユーザが行った処理においても同一のデータセンタ内または高速なネットワークでつながれたデータセンタ間内でコピーが行われるため、処理効率が高くなる。
3つ目は、RDF化処理後のデータもオープンにする点である。異なるユーザが同じ処理を行うことはコンピューティングリソース活用効率が悪い。そのため、RDF化処理後のデータも共有することで、ユーザ間で重複した処理をなくすことができる。他者が加工したRDFデータをさらに2次、3次加工するためにもこの特徴は、重要である。もちろん、データ利用者にとっては、公開されているRDFデータを用いることで、自ら加工処理を行う必要なく、アプリケーション開発に用いることができる。
※その他、課題、効果などは下記ページ参照
http://idea.linkdata.org/idea/idea1s1645i
[Linked Open処理の実装アイデア]
今回は、IBM Bluemixでの実装を検討した。IBM Bluemixには今回のサービスを開発するために必要なミドルウェアが用意されている。具体的には、以下のミドルウェアが有用である。
・RDF化処理(Node-RED)
RDF化処理実施者がRDF化処理を行う部分のミドルウェアとして、Node-REDが活用できる。今回、Node-REDをETLツールの様に用いる。しかし、Node-REDには従来のETLツールにない機能が数多く存在する。
1つ目は、外部APIとの連携である。Node-REDは元々IoT端末から取得したデータをGUI上で加工修正するために開発された開発環境であるが、現在はIoTの範疇にとどまらず、外部APIのマッシュアップ等さまざまな用途で活用されている。例えば、Watsonなど自然言語処理APIと連携する機能も盛んに開発されている。高度な処理を行うサービスは、外部のAPIとして提供されているケースも多いため、Node-REDの特徴を活用して取り込むことができる。
2つ目は、ソースコードの共有の手軽さである。Node-REDでのソースコードの共有は、JSON形式のデータをコピー&ペーストするだけで完結する。本実装では、ウェブ上でRDF化処理をライブラリ化しやすいNode-REDの特徴を活用する。
3つ目は、データ送受信を行う軽量なプロトコルMQTTに対応している点である。本実装では、1つのデータソースを入力とし多数のRDF化処理を実行する必要がある。MQTTはこのような複数の処理にデータをブロードキャストする様な使い方ができるプロトコルである。また、2つ以上のRDF化処理をMQTTを経由してつなげることで、リアルタイムに2つ以上の処理を順序性を持たせて実行することも可能である。特に、データの送信元のIDを指定するのみでデータを取り込めるため、開発者や実行したユーザが異なるRDF化処理を連結する場合に有効である。
・RDFストア(Graph Data Store)
RDF化後のデータを格納するには、Graph Data Storeを活用できる。本サービスは、Apache TinkerPopをベースとしたグラフデータベースであり、RDFストアと同等の機能を提供している。実装では、RDF化処理後のデータを本データベースに格納する。データを2次、3次加工する場合は、本データベースからデータを取り出して、RDF処理を行い、再度処理結果のRDFデータを書き戻す。またアプリケーションがRDFデータを参照したい場合は、本データベースのREST APIを用いてデータを参照する。
・データ加工サービス
データ加工サービスが新規に開発する必要がある部分である。本サービスは主に以下の機能を提供する。
- RDF化処理実施者にRDF化処理コードをウェブライブラリとして提供する機能
- RDF化処理実施者がGraph Data Store上のデータと、RDF化処理を指定すると、MQTT経由でデータのURIをNode-RED上のRDF化処理に渡し、RDF化処理を実行する機能
- 上記RDF化処理が出力したデータをMQTT経由で取得し、Graph Data Storeに格納できるようRDF形式と同等のデータに整形して格納する機能
[クラウドサービスで提供する理由]
本サービスは、Bluemixに代表されるようなクラウドサービスと相性が良いと考える。
1つ目として、データとコンピューティングとのネットワーク上の距離が近い方が、処理効率が良い点が挙げられる。近年のクラウドサービスは、世界中のデータセンタ間を高速なネットワークで接続されている。そのため、純粋なインターネット上のバックボーンを利用するよりも遥かにネットワーク転送効率が良い。これは、大規模なデータを扱うために必須の条件である。また、世界各地に点在するデータ提供者は、自分と近いデータセンタを選択することで、効率よくデータを提供できる。
2つ目は、コンピューティングリソースが豊富な点である。クラウドサービスの様な提供方法は、大量の計算を行う際に有効である。また、一般的な法則として、よく使われるデータや処理は実コンピューティングリソースやストレージリソースのほんの一部であることが多い。自前でサーバを用意するとこのようなケースは、費用がかかるが、クラウドサービスでは費用を最小限にできる。
3つ目はストレージが低価格である点である。料金上はペタバイト級のデータを現実的な費用で(かつ個人によるハードディスクメンテナンス不要で)、利用できる。
Update: Jan 18, 2016
(Kazuhito Yokoi)